Część 1. Bazy
danych – wstęp
1.
Co to jest baza danych? Po co stosujemy bazę danych?
Wady i zalety baz danych.
Definicja (niezbyt dobra) z Encyklopedii WIEM jest pod adresem http://wiem.onet.pl/wiem/007758.html .
Baza danych to zbiór uporządkowanych informacji (czyli danych). Na ogół przez bazę danych rozumie się również mechanizmy bazy danych służące do porządkowania, gromadzenia i usuwania danych. Zadaniem bazy danych jest na ogół komputerowa reprezentacja obiektów (listy obiektów) posiadających wspólne cechy. Baza danych umożliwia przede wszystkim szybkie i stosunkowo łatwe wyszukiwanie informacji.
Przykłady środowisk, w których można zastosować bazę danych to:
- Biblioteka:
Spis książek wspólna cecha obiektów to bycie książką w bibliotece. W bazie danych można umieścić na przykład tytuł książki, jej numer, autora, informację o tym czy książka jest wypożyczona, przez kogo, na jak długo i inne. W bazie danych można zapisać również spis listę osób, których wspólną cechą jest wypożyczanie książek z tej biblioteki, informacje na temat tych osób (adres, rok urodzenia itp.).
- Społeczeństwo:
Lista obywateli z danymi na ich temat do celów statystycznych, informacje o pokrewieństwie, adresach (które mogą stanowić odrębną listę w bazie z informacjami na temat budynków – łatwo wtedy wykryć np. fałszywy adres).
- Fabryka:
Dane o produkcji to oczywisty przykład, ale w takiej bazie można również gromadzić informacje o zdarzeniach w fabryce i ich wpływie na wydajność. Dzięki bazie danych w fabryce można również łatwo obliczać współczynniki wydajności dla różnych wydziałów czy osób (i na przykład na tej podstawie pensje w innej bazie danych).
- Wyszukiwarka www:
Lista odnośników URL do stron www, z informacjami o zawartości strony, słowach kluczowych, dacie utworzenia i modyfikacji, autorze itp. Obecnie liczba stron w Internecie jest tak duża, że nie jest możliwe stworzenie dobrej wyszukiwarki stron www bez szybkiej bazy danych.
Przykłady, zwłaszcza te zbliżone do biblioteki (sklepy, hurtownie, wypożyczalnie wideo, punkty usługowe) można mnożyć. Niezależnie od tego, czy jest to uzasadnione, czy nie, bazy danych są jedną z przyczyn powszechnej komputeryzacji. Z pewnością ich wadą jest stosunkowo duże niebezpieczeństwo zniszczenia bazy w porównaniu z bardziej tradycyjnymi metodami gromadzenia danych (bazę może uszkodzić wirus komputerowy, celowe działanie hakera, fizyczne uszkodzenie dysku, błąd użytkownika lub inne przyczyny zewnętrzne). Bazy danych o dużym znaczeniu muszą być wyposażone w mechanizmy backupu. Zalety to:
- porządek,
- szybkie wyszukiwanie informacji,
- łatwa modyfikacja informacji,
- łatwe przenoszenie danych do innej bazy lub tworzenie nowej bazy,
- mała objętość fizyczna bazy danych.
2.
Formaty i rodzaje (modele) baz danych
Można wyobrazić sobie bazę danych, która umieszczona jest w pliku tekstowym. Kolejne obiekty mogą być umieszczane w kolejnych liniach pliku, programem obsługującym może być zwykły notatnik. Niemniej takie rozwiązanie posiada szereg niedogodności, związanych z tym, że nie jest przeznaczone do przechowywania danych: trudno kopiować dane, łączyć dane w grupy na podstawie jednej wspólnej cechy (np. trudno wybrać książki wypożyczone z wszystkich książek w bazie, trudno umieścić w tej samej bazie listę użytkowników biblioteki). Dlatego do obsługi i tworzenia baz danych służy wyspecjalizowane oprogramowanie, które jednocześnie definiuje format bazy danych. Między innymi istnieją następujące formaty baz danych (czyli SZBD, czyli DBMS, DataBase Management System oprogramowanie do zarządzania, obsługi i tworzenia baz danych):
- Oracle – najsłynniejszy,
- MySQL – to będzie na zajęciach, przyda się m. in. do www pod php,
- Access – będzie na zajęciach, najprostszy format baz danych z punktu widzenia użytkownika i programisty, bardzo wygodny do szybkiego tworzenia baz danych i mechanizmów w bazie danych,
- dBase – trochę przestarzałe, pierwszy powszechny standard dla wielu baz danych (stąd niekiedy określenie xBase), np. dla FoxPro Microsoftu,
- Progress,
- Paradox,
- Mini SQL.
W miarę rozwoju baz danych zmieniały się również rodzaje (modele) baz danych. Poniżej wymienione są modele baz danych, począwszy od najstarszego:
- hierarchiczne bazy danych (zapomnieć): założenie, że dane można przedstawić w strukturze drzewa, na przykład dla bazy danych fabryki, między danymi istnieją związki „podległości”:
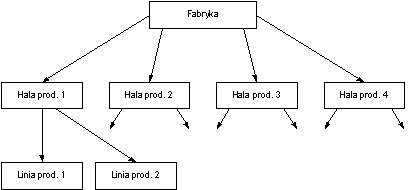
- sieciowe (grafowe) bazy danych (zapomnieć): podobne do tego, co wyżej, ale założenie, że dane można przedstawić w postaci grafu,
- relacyjne bazy danych – najpopularniejsze i bardzo wygodne, o tym będzie mowa, należy wiązać z pojęciem „tabeli”,
- obiektowe i relacyjno-obiektowe bazy danych – najnowsze, tworzenie bazy zgodnie z założeniami dla języków programowania obiektowego.
Poza wymienionymi można mówić o:
- dedukcyjnych (inteligentnych) bazach danych, współtworzących bazę na podstawie reguł wnioskowania,
- rozproszonych bazach danych, czyli rozproszonych sieciowo, obejmujących wiele komputerów (umieszczonych na wielu komputerach),
- jednopoziomowych (płaskich) bazach danych, czyli bazach danych złożonych z jednej listy, czyli tabeli obiektów; baza danych biblioteki zawierająca tabelę książek i czytelników nie jest już bazą jednopoziomową,
- hurtowniach danych, czyli dużych bazach danych, stworzonych na przykład z danych pochodzących z banku (wszystkie operacje finansowe) czy od operatora telefonicznego (wszystkie połączenia telefoniczne); dane w hurtowni danych muszą być dostępne zawsze (nigdy nie są usuwane), mają ten sam charakter, hurtownie danych powinny być wyposażone w narzędzia statystyczne i analityczne.
3.
Relacyjne bazy danych
Relacyjna baza danych to baza oparta na tabelach (zbiorach) danych i związkach między nimi. Idea została opracowana przez E. F. Codd’a, autora języka SEQUEL (nie mylić z SQL). Standardowym językiem do obsługi relacyjnych bazy danych jest SQL. Jego pierwowzorem był SEQUEL.
W relacyjnej bazie danych istnieją:
- tabele o unikalnych nazwach (mogą to być na przykład tabele operacji finansowych w banku),
- wiersze (krotki), w tabelach są elementami (obiektami) bazy danych, mogą to być na przykład książki,
- kolumny, mają unikalne nazwy w ramach tabeli i określają cechy obiektów tabeli, wszystkie elementy w tabeli są tego samego typu (formatu) – na przykład w jednej z kolumn mogą być daty wydania książek, wtedy formatem takiej kolumny będzie data.
Skąd pochodzi nazwa „relacyjna”? Relacja to inaczej iloczyn kartezjański zbiorów (wszystkie elementy jednego zbioru połączone w pary z wszystkimi elementami drugiego zbioru). Przecięcia wierszy i kolumn tabel (zawierające dane typu takiego, jak typ kolumny i dotyczące obiektu takiego, jaki opisuje dany wiersz) mogą być postrzegane jako element iloczynu kartezjańskiego dwóch zbiorów: zbioru danych w kolumnie i zbioru cech elementu. Oczywiście kolumn może być wiele, wtedy nie mówimy o parach elementów ale o większej liczbie kombinacji elementów z większej liczby zbiorów. (zapomnieć, wg mnie ta nazwa nie jest najszczęśliwsza).
Przykład tabeli z relacyjnej bazy danych wygląda tak:
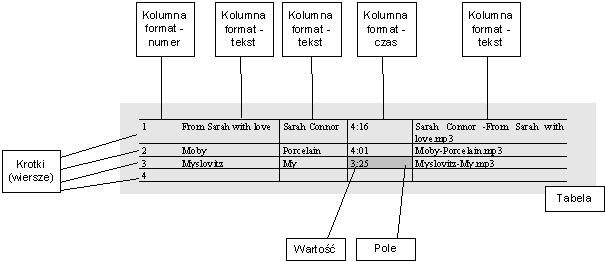
Przecięcie wiersza z kolumną w tabeli może mieć tylko jedną wartość. Może to być wartość pusta (brak wartości) – NULL. Każda tabela ma klucz główny, czyli kolumnę jednoznacznie identyfikującą element tabeli (wiersz, krotkę). W powyższym przykładzie jest to numer po lewej stronie. Klucz główny nie może mieć wartości NULL. Klucz główny należy zawsze wyznaczać bardzo ostrożnie. W powyższym przykładzie nie może to być tytuł piosenki (może się powtórzyć), nie może być to wykonawca, nazwa pliku również może się powtórzyć w dwóch różnych katalogach (ale pełna ścieżka do pliku mogłaby być). Zawsze uniwersalnym rozwiązaniem jest wprowadzenie kolumny, która zawiera kolejne numery elementów. Jest to stosowane na przykład w bibliotekach, gdzie każda książka ma swój numer – niezależnie od tego czy baza biblioteki znajduje się na papierze (w kartotece) czy w komputerze.
4.
Kilka uwag na koniec początku
Do projektowania relacyjnych baz danych należy podchodzić z uwagą. Baza powinna być zaprojektowana z możliwie największą prostotą. Od przyszłych użytkowników bazy należy uzyskać informacje o tym, czego oczekują od bazy – obecnie i w przyszłości.
Należy wystrzegać się łączenia obiektów różnego typu w jednej tabeli, przykładem złego projektu bazy dla biblioteki byłaby taka baza, która miałaby jedną tabelę zawierającą równocześnie czytelników i książki. Należy pamiętać, że baza danych gromadząca zdarzenia może szybko zwiększać objętość. Dla takich baz trzeba przewidzieć mechanizmy usuwania zbędnych, przestarzałych danych, ew. archiwizacji lub kompresji.
W czasie tego kursu będzie mowa wyłącznie o relacyjnych
bazach danych. Kurs obejmie
DBMS MSAccess i MySQL.